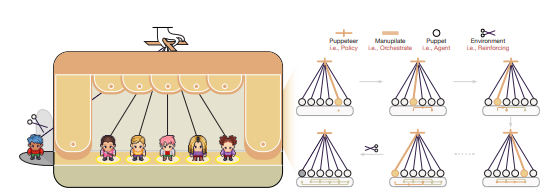
Dec. 02, 2025 /Mpelembe Media/ — The academic paper introduces a novel framework for coordinating complex problem-solving in Large Language Model (LLM)-based multi-agent systems. To address the inherent inefficiencies of traditional static agent structures, the authors propose a “puppeteer-style” paradigm where a central orchestrator dynamically selects and sequences agents based on the evolving task state. This centralised orchestrator policy is continuously optimised using reinforcement learning (RL), leveraging a tailored reward function that explicitly balances solution quality with computational efficiency. Empirical results across various closed- and open-domain scenarios demonstrate that this adaptive approach achieves superior performance compared to existing methods while concurrently reducing token consumption. Finally, analysis of the evolving collaboration patterns confirms that the RL-driven policy leads to the emergence of highly compact and cyclic reasoning structures. Continue reading
02Dec/25