From Static Reports to Sensing Engines: Rebuilding Corporate Strategy for the Agentic Era
Thur, July 03 2026 /Mpelembe Media/ —Agentic AI is fundamentally restructuring corporate intelligence by shifting market research and competitor monitoring from slow, episodic project cycles into always-on, real-time “sensing engines”. This architectural shift automates the extraction of competitor movements, SEC filings, pricing changes, and customer sentiment to dramatically compress decision latency. However, as organizations attempt to scale these autonomous systems, they face a deep tension between the efficiency of synthetic simulation and the necessity of rigorous human-led governance.
Core Themes & Insights
- The Evolution to Always-On Competitor Sensing: Traditional competitive intelligence operates retroactively, leaving strategic teams vulnerable to sudden market changes. Modern agentic pipelines (utilizing specialized platforms like ciATHENA, V7 Go, and Contify) continuously monitor digital footprints—such as competitor pricing tables, SEC 10-Q/10-K filings, product updates, and executive hires—to build a dynamic, 360-degree view of the market. By turning static historical data into an auto-updating, interactive asset, commercial teams can run predictive simulations (such as testing price elasticity or message options) before committing budgets.
- The Synthetic Participant Paradox: While synthetic user platforms (such as DeepSights, Qualtrics, and SYMAR) promise to eliminate the high costs and logistical delays of recruiting human participants, extensive research reveals serious constraints. A comprehensive systematic literature review of 182 papers on synthetic participants highlights four critical failure modes: cognitive misalignment, representation distortions, misleading believability, and overfitting/contamination. While persona-conditioned LLMs can successfully brainstorm hypotheses and outline expected structures, they exhibit a strong “rationality bias”, struggle to capture true attitudinal variance, and frequently misrepresent or flatten marginalized subgroups.
- The Operational Mandate of Human-in-the-Loop (HITL) Governance: Because autonomous agents execute actions across live systems rather than merely advising, unregulated agentic execution introduces severe liabilities, including hallucinations with legal consequences, prompt injection vulnerabilities, and systemic compliance failures. To safely deploy these agents, enterprises are implementing structured HITL and Human-on-the-Loop (HOTL) frameworks. Leading paradigms shift governance away from static policy documents toward “Policy-as-Code”—technical identity controls, API permission boundaries, and sandbox environments that act as deterministic circuit breakers the agent cannot bypass.
The Agentic Shift: 5 Surprising Realities of the AI Agent Revolution
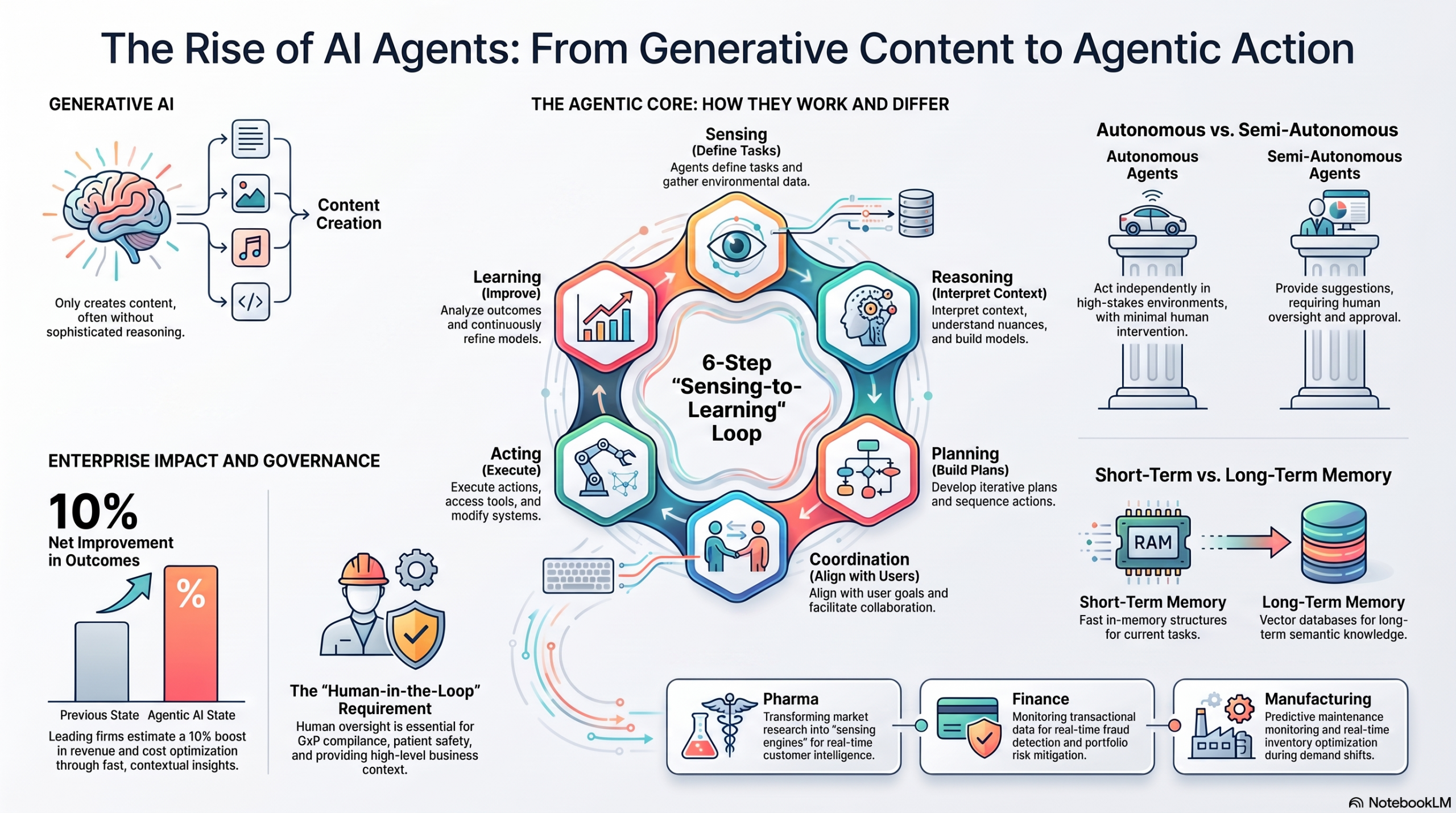
The first wave of the Generative AI hype cycle was defined by a simple, if limited, interaction: the prompt and the response. We asked a chatbot to summarize a meeting or write an email, and it complied. But we have reached the architectural limits of the “chatbot” era. We have all experienced the state management failure: you ask an AI to book a flight, check your calendar, and draft a confirmation email, and somewhere between steps two and three, it “forgets” the flight details it just looked up.The shift toward Agentic AI represents a move away from simple chatbots toward autonomous “sensing engines.” These are systems designed not just to talk, but to do —reasoning through multi-step problems, sifting through information sources, and executing plans without constant human hand-holding. However, moving from a demo to a production-ready agent reveals five surprising realities that challenge our current understanding of artificial intelligence.
1. The “Persona” Paradox—When More Detail Leads to Less Accuracy
A common practice in AI development is “persona prompting”—giving an LLM a detailed demographic profile to simulate a specific type of user. We assume that the more detail we provide (age, education, income), the more accurate the simulation. However, the study “Assessing the Reliability of Persona-Conditioned LLMs” suggests otherwise.Researchers evaluated two prominent open-weight models— Llama-2-13B and Qwen3-4B —across more than 70,000 respondent-item instances from the World Values Survey. They discovered that adding multi-attribute demographic personas does not yield a clear aggregate improvement in alignment; in fact, it often significantly degrades performance.”Persona effects are highly heterogeneous as most items exhibit minimal change, while a small subset of questions and underrepresented subgroups experience disproportionate distortions… demographic conditioning can redistribute error in ways that undermine subgroup fidelity.”For companies trying to use “silicon samples” for market research, this is a wake-up call. Over-conditioning a model can caricature social groups and distort data for marginalized populations. As an architect, I see this as a “redistribution of error” problem: by forcing the model into a narrow demographic box, you often break its underlying reasoning calibration.
2. Infrastructure Over Inference—Why the Model Matters Less Than the Pipeline
The gap between a flashy demo and a reliable production agent isn’t filled by a better model; it’s filled by systems engineering. Production reliability is a pipeline problem. To function at scale, an agent requires sophisticated state management and retry logic to handle transport failures (rate limits) versus logic failures (malformed tool calls).Infrastructure providers like Redis and Snowflake emphasize that “your agent infrastructure matters as much as your model.” To prevent the “memory loss” common in early GenAI, production agents must utilize a three-tier memory architecture:
- Short-term memory: The agent’s working memory, including the current conversation and active task state. This requires sub-millisecond latency to minimize the “latency tax” across repeated loops. Architects use in-memory data structures like Redis hashes, JSON, or sets to keep this fast.
- Long-term memory: The repository for semantic and episodic knowledge. This involves vector search and tools like Redis LangCache to optimize token usage and recall specialized knowledge across sessions.
- Operational State: A record of the system’s current progress and intermediate results. For long-running tasks, storing state externally is more reliable than depending on a disappearing context window.
3. The “Sensing Engine” vs. The Static Report
In industries like pharmaceuticals, traditional market research is “episodic.” Insights are delivered in static PDF decks that take weeks to produce. This “rearview mirror” intelligence is a liability; in fact, ZS has observed that one-third of clinically differentiated launches fail to meet expectations because the “sensing engine” wasn’t built to deliver real-time intelligence.Agentic AI transforms this into “always-on” intelligence. By building “First-Party Intelligence” —a proprietary asset no competitor can buy—organizations move from one-off readouts to a living intelligence layer.”Intelligence locked in decks never becomes an asset… The real cost of siloed insights isn’t inefficiency. It’s the decisions made without the full picture.”In this paradigm, humans become the “orchestrators” of intelligence. Think of the “Tony Stark” analogy: the AI acts as the Mark XLIV suit, handling the execution, data synthesis, and simulation of hundreds of positioning variants. The human provides the “interpretive leap,” focusing on judgment and strategy while the “sensing engine” monitors field signals and competitive responses in real time.
4. The Paradox of Autonomy: Trust is Built Through “Interrupts”
Human Oversight is a Feature, Not a Bug
Total autonomy is often viewed as the end goal, but in high-stakes fields like healthcare and finance, it is a liability. Regulatory frameworks like Good Practice (GxP) require documented authorization for sensitive operations. Deleting patient records or modifying clinical protocols simply cannot proceed without human sign-off.According to AWS and Insight Global, trust is built through four primary “Human-in-the-Loop” (HITL) methods:
- Agentic Loop Interrupts: Intercepting tool calls at the framework level before execution to enforce blanket policies.
- Tool Context Interrupts: Fine-grained, role-based access logic embedded within the tool itself (e.g., only a Physician can authorize a discharge).
- Remote Asynchronous Approvals: Using AWS Step Functions and Amazon SNS to pause an agent and notify a third-party supervisor via email or Slack.
- MCP Elicitation: Leveraging the Model Context Protocol to allow servers to request business justifications from humans via server-sent events (SSE) or WebSockets for real-time interaction.Human-led AI is the only way to scale in regulated environments where accountability remains a human responsibility.
5. Specialization is Eating Generalization (Data Agents vs. AI Agents)
We are seeing a divergence between general-purpose agents and specialized “Data Agents.” As Snowflake clarifies, the technical barrier for non-technical users is being dismantled not by a “god-model,” but by specialized intermediaries.Data Agents vs. General AI Agents:
- Data Agents: Specialized tools that combine LLMs with data engineering. They excel at SQL generation , identifying data anomalies , and orchestrating complex data pipelines within the data lake.
- General AI Agents: Broader, goal-driven systems that operate across domains, such as navigating robotics, playing games, or managing general customer support.This specialization allows a business lead to query a complex data lake using natural language, democratizing access to enterprise insights without waiting in a data science queue.
Conclusion: Beyond the Prompt
The winning move in the agentic revolution isn’t simply buying the most powerful model. It is building a proprietary intelligence layer that your competitors cannot buy. By connecting primary research, operational data, and rigorous human oversight into a single sensing engine, organizations move from reactive responses to proactive strategy.The shift to agents changes the fundamental contract between a business and its data. It moves us from “What does the data say?” to “What should we do next?”If your AI agent could run a thousand simulations of your next product launch tonight, are you prepared to act on what it finds tomorrow morning?