Curing the Context-Assembly Bottleneck: An Inside Look at the Open Knowledge Format
Wed, Jun 17 2026 /Mpelembe Media/ — The Open Knowledge Format (OKF) v0.1 is an open, vendor-neutral specification created by Google Cloud to standardize how organizational knowledge is packaged, shared, and consumed by AI agents and human teams. It formalizes the popular “LLM-wiki” pattern into a highly portable format, eliminating the need for custom integrations, proprietary software development kits (SDKs), or vendor lock-in.
The Problem It Solves OKF was designed to solve the “context-assembly bottleneck”. In most enterprises, the knowledge that foundation models need to perform actionable tasks—such as database schemas, metric definitions, incident playbooks, and API documentation—is scattered across fragmented surfaces like metadata catalogs, shared drives, unindexed wikis, and the minds of senior engineers. OKF aims to prevent every AI team from solving this assembly problem from scratch by turning these scattered sources into a common, agent-readable structure.
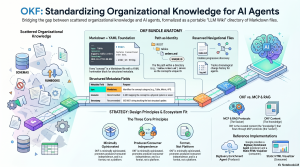
How It Works The design of OKF is intentionally minimal:
- Structure: An OKF “bundle” is simply a directory tree of plain text Markdown files, where each file represents a single unit of knowledge or “concept”.
- Formatting: Each concept document contains a YAML frontmatter block at the top for structured metadata, followed by a free-form Markdown body.
- Requirements: The specification is highly tolerant; the only strictly required YAML field is type (e.g., BigQuery Table, Playbook, Metric). Recommended but optional fields include title, description, resource, tags, and timestamp.
- Navigation: Concepts link to one another using standard Markdown hyperlinks, naturally forming a rich knowledge graph. Bundles can also use an index.md file to provide a directory listing for progressive disclosure, and a log.md file to maintain a chronological history of changes.
How OKF Compares to Existing AI Standards
- Versus RAG: While Retrieval-Augmented Generation (RAG) relies on vector databases to dynamically pull chunks from massive, unstructured document corpora at query time, OKF serves a different purpose. It acts as a curated, stable, human-maintained knowledge layer that is small and structured enough for an agent to load directly into its context window.
- Versus MCP: The Model Context Protocol (MCP) acts as the runtime “socket” that governs how AI agents connect to tools and live data. OKF, on the other hand, is the structured knowledge that flows through that socket. An MCP server can easily expose an OKF bundle as a standardized knowledge source.
Getting Started To demonstrate how OKF can be produced and consumed, Google Cloud published several reference implementations on GitHub alongside the specification. These include an enrichment agent that can crawl a BigQuery dataset to draft OKF concept documents automatically, a static HTML visualizer that renders any bundle into an interactive graph without a backend, and three sample bundles covering GA4 e-commerce, Stack Overflow, and Bitcoin public datasets. Because OKF consists solely of Markdown and YAML, it natively lives in Git repositories, allowing organizations to manage knowledge with the same version control and peer-review rigor as software code.
Why Your AI Agents Are Lost: Google’s New Open Knowledge Format (OKF) Wants to Be the Industry’s Shared Brain
Modern engineering teams are hitting an invisible wall in AI agent development: the gap between a powerful foundation model and a useful business result. You may have an agent sophisticated enough to refactor legacy Java, yet it fails when asked to generate a report on “Active Users.” It lacks the curated context to know which table holds the ground truth, how the SQL join paths are structured, or that the “Sales” definition changed during last week’s sprint.This friction stems from the “Context-Assembly Problem.” Critical organizational knowledge remains scattered across incompatible silos—proprietary metadata catalogs, unindexed wikis, Slack threads, and the “tribal knowledge” stored in senior engineers’ heads. On June 12, 2026, Google Cloud introduced the Open Knowledge Format (OKF) v0.1 to dismantle this wall. Released under the Apache 2.0 license , OKF isn’t a new product to buy, but an open-source “shape” the industry can use to package institutional memory into a shared brain.
1. Solving the “Context-Assembly” Bottleneck
Fragmentation forces every developer building an AI agent to solve the context-assembly problem from scratch. Current workflows require bespoke parsers for documentation and custom integrations for metadata APIs. As the Google Cloud announcement observed:“As foundation models continue to improve, the lack of relevant context often limits what they can do, especially as they are used to build agentic systems… they still need the right information to produce accurate and actionable results.”OKF standardizes this interoperability layer. Proving the format’s immediate utility, Google updated its Knowledge Catalog (formerly Dataplex) at launch to natively ingest OKF bundles. This shift allows curated metadata to move seamlessly between humans, agents, and tools without a custom connector for every new service in the stack.
2. Knowledge as Code—The “Karpathy Pattern” Goes Enterprise
The technical lineage of OKF traces back to the “LLM Wiki” pattern popularized by researcher Andrej Karpathy. The core insight is that Markdown serves as the ideal medium for AI memory: it is human-readable, machine-parseable, and “diff-able” in Git.By treating knowledge as code, organizations can manage business logic with the same rigor as software. OKF bundles reside in secure Git infrastructure, inheriting the entire ecosystem of versioning, pull-request reviews, and granular access control. This bridges the historical gap between Data Governance and DevOps.Crucially, this pattern addresses “wiki rot.” Human-maintained wikis usually die because the bookkeeping—cross-references and manual updates—is tedious. AI agents, however, excel at this precise task. As Karpathy noted:“LLMs don’t get bored, don’t forget to update a cross-reference, and can touch 15 files in one pass.”
3. A “Format,” Not a Platform—The Power of Minimalist Design
OKF is “minimally opinionated” to ensure it remains portable across any cloud or vendor. An OKF Bundle is a directory of Markdown files, each representing a Concept (a table, metric, or runbook). While the specification formally requires only one field—type—in the YAML frontmatter, Google’s reference implementation establishes a higher bar for quality.The format suggests five primary fields for maximum utility:
| Field | Description |
|---|---|
| title | A clear, human-readable label. |
| description | A qualitative summary of the concept. |
| resource | A URI mapping the concept to a physical system (e.g., a BigQuery URL). |
| tags | For arbitrary filtering and discovery. |
| timestamp | To track the last structural update. |
4. Knowing the Stack: OKF vs. MCP vs. RAG
Understanding where OKF fits in the emerging AI stack is vital for architects. It doesn’t replace the Model Context Protocol (MCP) or Retrieval-Augmented Generation (RAG); it optimizes them.
| Technology | Strategic Role | Practical Analogy |
|---|---|---|
| MCP | The Socket | The runtime interface that connects the agent to a tool. |
| RAG | The Search | The mechanism for finding fragments in massive, unstructured data. |
| OKF | The Knowledge | The curated, “compiled” metadata and stable business facts. |
By providing agents with curated concepts rather than raw, unorganized documents, OKF yields a massive efficiency gain. In focused domains, a well-maintained Markdown library can reduce token consumption by up to 95% compared to naive document loading. OKF provides “compiled” knowledge, allowing the agent to skip the process of re-discovering relationships during every inference pass.
5. The “v0.1” Reality Check: Architecture and Limitations
As a “Draft” standard, OKF v0.1 has specific implementation nuances that early adopters must navigate.
- The Semantic Gap: There is no central registry for type values. One team might use “BigQuery Table” while another uses “table.” Architects must define an internal vocabulary to ensure consistency across their agents.
- The 4-Field Discrepancy: While the SPEC.md identifies only one mandatory field, the Python reference implementation (validation logic) enforces four: type, title, description, and timestamp.
- The Two-Pass Blueprint: Google’s reference enrichment agent provides a roadmap for building reliable producers. It uses a two-pass architecture :
- Discovery: Walking the dataset to draft skeletal concept documents from technical metadata.
- Enrichment: Crawling authoritative documentation to add citations, join paths, and business context.
Conclusion: Toward a “Lingua Franca” for AI
The Open Knowledge Format signifies a fundamental pivot toward data sovereignty . Because OKF is purely file-based, your company’s most valuable intellectual property remains in your control—not locked in a vendor’s proprietary database. This makes OKF a critical component for a GDPR-compliant AI stack; your files live on your infrastructure, in your jurisdiction, with a cryptographic audit trail provided by Git.As we move toward an “Agentic Web,” the strategic question for leadership changes. It is no longer enough to ask, “Which models are we using?” You must ask: “Is our institutional knowledge agent-ready?”If your business logic is trapped in silos an AI cannot navigate, your agents will remain lost. OKF offers the industry a way to build a shared, versioned brain—one Markdown file at a time.